Hey Folks,
just a really quick one. It may be that you are planning to upgrade your SBC from a version <8 to 8.x or the release.
If so, the following could apply. If your peer is sending you messages like the following:
SIP/2.0 500 Server Internal Error
Call-ID: [email protected]
CSeq: 2 INVITE
From: „One of our users“ ;tag=ac146309-538b4;sgid=3
To: ;tag=SDpadk899-0082-000007ff-0390i0
Via: SIP/2.0/TCP 172.172.172.172:5060;branch=z9hG4bK-UX-ac14-6309-2d639
Content-Length: 0
Reason: Q.850;cause=34
Retry-After: 10
It may happen that your Ribbon SBC Edge is going to disable the used Signalling Group for the timer specified (in seconds)
It does not need to be a 500 Server error message, it could be any other kind of Error as well. After the mentioned time frame the SBC will put the Signalling Group online again.
Why is that and how to work around?
According to Ribbon Engineering in 8.0 and later the SBC has been modified to be compliant to RFCs in terms of the Retry-After header handling. The SG will drop for the amount of time that is in the Retry-After header.
This will be normal operation starting with 8.0 and higher.
| SYM-25553 | Handling the Retry-After header for calls |
One can fix this by creating some inbound SIP Message Manipulation for the peer that is sending this kind of errors / header. It should be noted that while the SMM will prevent the SG from dropping; calls will still fail; until the peer device has recovered.
- But on the positive side it is just the one call that the Provider sends an error for and not all active/upcoming calls.
- The possible negative impact of the SMM: the SBC may still try more calls to the peer; while the peer is not accepting calls and this has the potential of making the issue bigger on the other side.
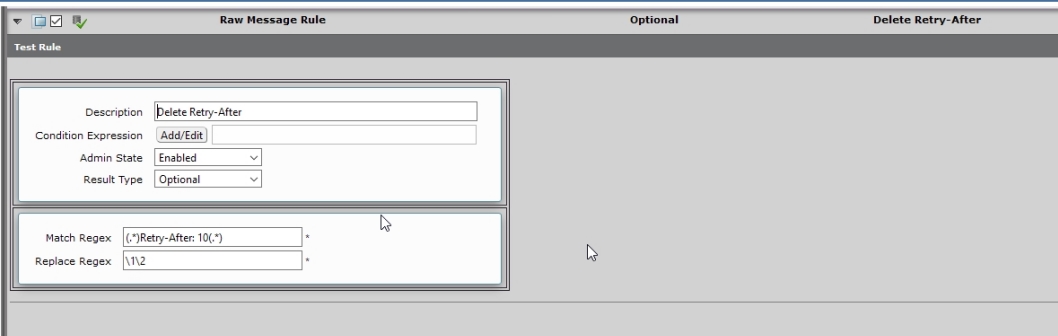
My Example SMM only applies if the value of the Retry-After header is about 10 seconds. If your peer would send you other values you would need to add additional rules.
In the past I played around with the SMM to get one rule applying all possible matches. But working with a rule like: (.*)Retry-After: .*(.*) – is not possible.
Because the SBC does not know where the Retry-After value ends and where other content starts. Even if your peer sends „always“ the same header after the one we want to cut off… it would more be guessing than a structured rule at the end.
Happy to get any comments or a hint how to match this header value-independent 😉
Cheers,
Enrico
PS: relevant RFC sections:
https://tools.ietf.org/html/rfc3261#section-14.1
https://tools.ietf.org/html/rfc3261#section-20.33